Prevendo o preço de imóveis com Machine Learning – Parte 2
Sempre que um fundo imobiliário quer revender uma casa, o objetivo é conseguir colocar o maior preço possível para conseguir um bom retorno financeiro sob a venda. E é até possível termos alguns indícios de faixa de preços de acordo com a casa, uma maior custará mais do que uma menor, ou talvez as mais novas custem mais do que as antigas. Mas será que é isso mesmo? Vamos descobrir juntos dando continuidade ao estudo de caso, utilizando mais uma técnica de Machine Learning.
Aplicamos na parte 1 deste artigo, técnicas de análise descritiva para observar como as características das casas influenciaram no valor. E agora através de Modelos de Machine Learning, vamos prever o valor que o fundo imobiliário conseguirá colocar nas casas novas para conseguir revendê-las ao ponto de otimizar o ROI e todas suas ações de vendas.
Vamos lá?
*** Importante: continuaremos utilizando o banco de dados do Kaggle.
Modelos de Machine Learning
De maneira simplificada, Modelo de Machine Learning é um algoritmo ou equação matemática que transforma as variáveis explicativas em uma de interesse, a que queremos predizer. Ou seja, aqui iremos partir do ponto das características que já conhecemos do imóvel e ver o histórico de vendas, para conhecer o preço de uma casa nova.
Na imagem abaixo a imagem exemplifica a ideia geral por trás de um modelo:
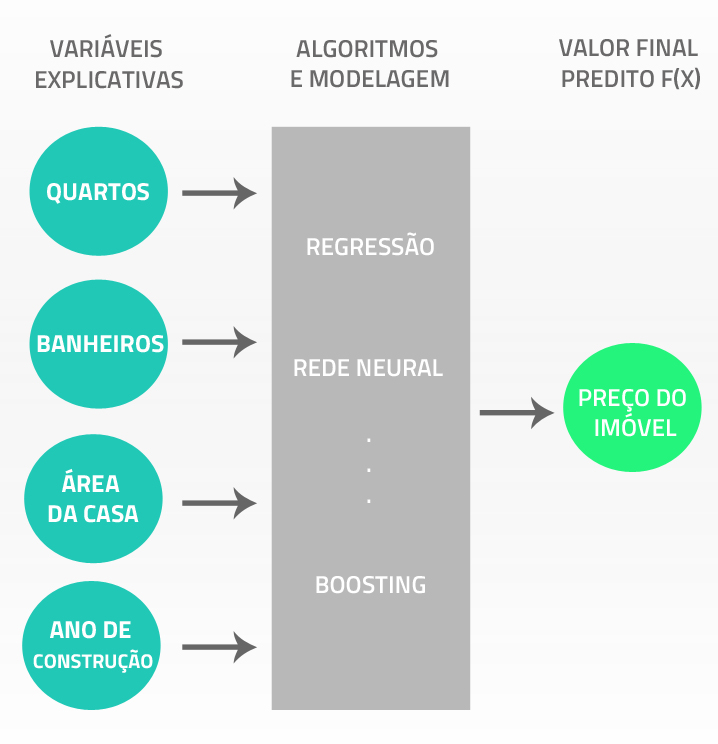
A ideia do modelo é a seguinte: passamos certos inputs ou variáveis explicativas, ilustradas pelas bolas azuis para o algoritmo, que fará uma certa transformação nos dados gerando apenas um valor final, que é o valor que foi predito.
Não há um tipo de modelo que seja ideal em toda as situações, pois depende do cenário que está sendo trabalhado e das particularidades de cada base de dados. Além disso, não necessariamente um modelo com uma estrutura mais complexa será o melhor (por exemplo: uma Rede Neural comparada com uma Regressão Linear).
Há alguns modelos que são mais conhecidos, como por exemplo modelos que penalizam variáveis explicativas correlacionadas; uma regressão linear; uma floresta aleatória, entre outros. Por isso, recomendamos a leitura do artigo “10 Algoritmos de Aprendizagem de Máquinas (Machine Learning) que você precisa saber” e do livro “The Deep Learning textbook”, que aborda a fundo os modelos de Machine Learning e comenta sobre Deep Learning – campo que utiliza modelos de rede neural.
Além dos diferentes tipos de modelos, há várias maneiras de otimizar quanto o modelo irá acertar, que é o foco: quanto mais acertos, mais a nossa predição será boa.
Prevendo o preço do imóvel
O modelo que foi selecionado para fazer a predição do preço dos imóveis foi o Gradient Boosting Regressor. Vamos supor que três clientes foram até o fundo imobiliário e querem casas com as especificações da imagem abaixo, e agora precisamos predizer quanto deve ser cobrado nos imóveis de cada um dos clientes.
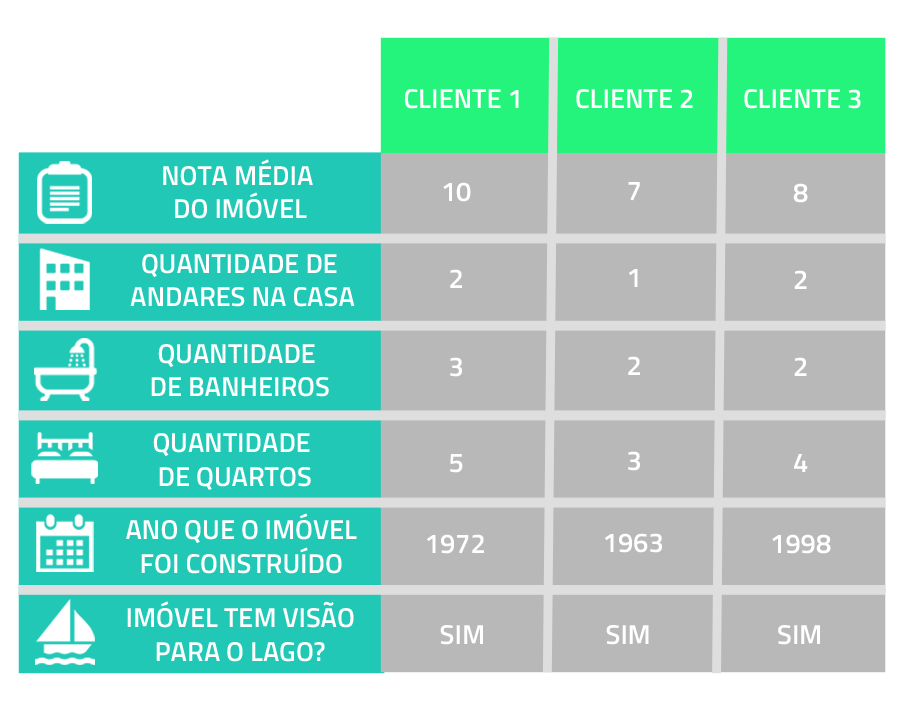
Você se lembra dos insights obtidos na parte 1 do artigo? O fundo imobiliário já sabe que a casa do cliente 1 custará mais, pois tem uma nota média alta, 3 banheiros e 5 quartos – e vimos anteriormente que essas são as características que as casa mais caras possuíam.
E em relação ao cliente 2 e 3, qual imóvel deve ser o mais caro? Se fosse para dizer sem o modelo, diríamos que é o do cliente 3, por possuir uma nota e quantidade de quartos maior em comparação a casa do cliente 2. Mas como podemos analisar no resultado da predição abaixo, mais uma vez nosso “achismo” estava errado!

O preço do imóvel do cliente 2 deve ser maior. Como eu disse anteriormente, o nosso banco de dados contém muitas outras variáveis além das que estão na figura acima. Ou seja, uma delas influenciou para que o modelo conseguisse entender e aprender que o imóvel do cliente 2 deveria ser maior.
As características das casas apresentadas acima – utilizando os três clientes fictícios – são observações presentes no banco de dados, exatamente para que conseguíssemos comparar o preço predito com o preço real do imóvel.
E o resultado da predição não está errada: o imóvel do cliente 2 realmente tem um valor superior ao cliente 3, e o preço do imóvel do cliente 1 é o maior! Isso significa que nosso modelo está acertando e predizendo o preço certo de acordo com as características dos imóveis.
Informações valiosas
Em resumo, aplicar esta técnica ajudaria o fundo imobiliário a prever o preço das casas para estes três diferentes clientes. Tanto a análise descritiva que fizemos na parte 1 como o modelo aplicado agora agregariam valor ao negócio do fundo, além de dar muito mais inteligência e eficiência em suas tomadas de decisões.
Nesta série, exploramos muitos dados disponíveis e vimos que usando algumas técnicas de Ciências de Dados e Machine Learning nos trouxeram informações valiosas. Mas, te garantimos, que não fizemos nem metade do que poderíamos ter feito.
Esperamos que o estudo de caso tenha te ajudado a avançar neste universo incrível que é a Ciência de Dados, e que tenha despertado o interesse a ponto de você estar considerando usar a inteligência de dados ao seu favor.