Implementação de Machine Learning: Do início ao fim
Embora este conceito já exista há décadas, a implementação de Machine Learning, ou no bom português Aprendizado de Máquina, no negócio é a grande aposta do momento, líderes dos mais variados tipos e tamanhos de empresas estão discutindo como inserir essa tecnologia em suas organizações para obter uma série de benefícios na busca de processos mais eficientes e resultados mais assertivos.
No entanto, muitas organizações se frustram nessa jornada por não saberem tirar real valor dessa tecnologia, e, consequentemente, não alcançam as melhorias necessárias. Em nossa vivência e expertise com diversos projetos de Machine Learning, percebemos que em sua maioria quando isso ocorre, é porque a empresa tem dificuldade de entender como implementar corretamente para atender seus objetivos de negócio.
Neste artigo, vamos percorrer do início ao fim do que precisa ser levado em consideração em uma implementação de Machine Learning para garantir modelos de sucesso.
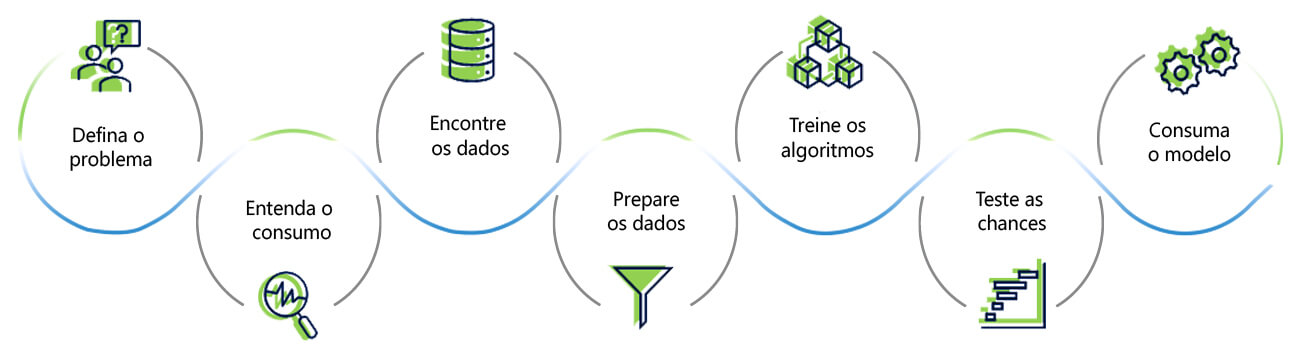
1) Defina o problema
Em projetos de TI, Ciência de Dados, arquitetura ou até mesmo em áreas de negócios o pontapé inicial se dá a partir de um problema que precisa ser definido, entendido e explorado. Afinal, você pode estar utilizando as tecnologias mais poderosas, manuseadas por profissionais experientes, mas os resultados serão desastrosos se você não estiver resolvendo o problema certo.
Nesta etapa, também é de suma importância avaliar os impactos positivos e negativos que podem ser gerados e entender a importância da vigilância constante desses sistemas durante e pós sua implementação. Tendo esses três pontos bem definidos já será possível definir quais serão as características das observações, o tipo de algoritmo e testar hipóteses para ver o quanto isso poderá ajudar no seu problema.
Para ilustrar este passo a passo, vamos imaginar uma corretora de seguros que quer prever a renovação de apólice de planos corporativos de saúde. Isso em si é o resultado que a empresa deseja alcançar, o problema de fato nesse caso poderia ser: Quais organizações/clientes estão mais propensas a não renovar o seu plano para que, com este conhecimento, a corretora possa entrar com ações efetivas para garantir ou aumentar a probabilidade de renovação, como por exemplo oferecendo descontos, melhorando o atendimento, etc.
Para abordar esse problema em específico usaremos um algoritmo de Classificação por ser aplicado para respostas que se enquadrem em sim ou não – no qual o ‘sim’ significa que a empresa está propensa a renovar o seguro e ‘não’ quer dizer que o cliente provavelmente irá cancelar o serviço.
2) Entenda o consumo
De que forma seu modelo precisará atuar para resolver seu problema? O Machine Learning será aplicado uma única vez? Ou de tempos em tempos? Os dados precisam ser em real-time ou serão utilizados dados frios?
Dependendo das necessidades do seu problema, a implementação de Machine Learning poderá precisar de uma arquitetura de dados para extração e armazenamento, que deverá ser construída paralelamente. Em outros casos, a conexão com um sistema existente é o suficiente. Mas as vezes a resolução é tão simples que apenas um relatório ou um dashboard já basta.
Neste tópico, o mais importante é automatizar o modelo criado e ter um time experiente para orientar o melhor caminho e garantir toda a segurança das fontes de dados que vão servir o modelo de ponta a ponta, por isso:
- Opte por plataformas robustas;
- Armazene essas origens com chaves criptográficas;
- Crie etapas de autenticação e autorização.
3) Encontre os dados
Depois de identificar o problema e como será o consumo do modelo, você precisará entender quais tipos de dados o Machine Learning irá precisar para resolver a questão e atingir o resultado esperado, afinal algoritmos aprendem com dados.
No caso do exemplo da corretora de seguros, seria preciso ter uma base atual de empresas que estão próximas da data de renovação da apólice do plano de saúde, e, para entender quais tem maior ou menor probabilidade de renovar o seguro, seria preciso levantar características de observação como: regionalização, nº de funcionários, média da faixa de idades, formas de pagamento, entre outros. São esses dados que irão ajudar nosso modelo a encontrar padrões.
Como estamos trabalhando nesse exemplo com algoritmo de Classificação, que é um tipo Supervisionado, em que a máquina tem o total entendimento dos resultados certos, precisaríamos também de uma base histórica de empresas que no ano anterior tinham o seguro, mas não renovaram as apólices, para entendermos o porquê da desistência e para que o ML compare as duas bases e identifique as características em comum.
É importante ressaltar que com Lei Geral de Proteção de Dados (LGPD) – que estabelece regras sobre coleta, armazenamento, tratamento e compartilhamento de dados pessoais – em vigor se torna obrigatório o trabalho com bases de dados legais, a comunicação com transparência e a fidelidade para informar quais serão os dados coletados, para quais finalidades (não podendo ser alterado o seu fim), garantindo proteger e respeitar a privacidade do usuário.
Por isso, se possível:
- Evite o uso de dados sensíveis – principalmente se identificarem uma pessoa física;
- Caso seja imprescindível o uso faça um processo de anonimização de dados para não ferir e proteger a privacidade do indivíduo;
- Utilize o mínimo necessário para evitar o uso indevido de dados.
4) Prepare os dados
Para aplicar aprendizado de máquina, você precisará não apenas de um bom volume de dados, mas também em alta qualidade. É difícil aplicar essa tecnologia se os dados fornecidos não forem consistentes. Por isso, é preciso que seja feita toda a formatação e limpeza desses dados para que não haja informações incompletas ou repetidas. Durante todo esse processo não esqueça de incluir segurança, uma autenticação reforçada e de gerir a autorização dos dados.
Outra prática necessária para evitar viés no resultado é separar uma parte dos dados para testar o modelo. Dessa forma toda informação aprendida será extraída de uma base de treino e testada em outra base totalmente distinta.
Assim, você entregará para seu modelo todas as observações e ele aprenderá e encontrará quais são as características de cada (no nosso exemplo seria regionalização, nº de funcionários, média da faixa de idades, formas de pagamento etc.) das empresas que não renovaram apólice. Evitando que o modelo “decore” as respostas e permitindo o maior nível de generalização possível.
5) Treine os algoritmos
É nesse ponto que vamos enfim começar a treinar nosso algoritmo. Para isso, você irá utilizar a base atual já tratada, que no caso do nosso exemplo seria de empresas que estão próximas da data de renovação da apólice do plano de saúde, para que o algoritmo identifique quais delas tem menos probabilidade de renovarem o seguro.
Supondo que nossa base tenha 10 mil empresas, o seu modelo irá olhar um por um, comparando com os dados históricos até conseguirmos visualizar o percentual de acurácia da aderência do modelo em relação as informações que estamos trabalhando.

6) Teste e verifique as possibilidades
Após treinar alguns algoritmos para identificar quais são as características que descrevem as observações sendo feitas, entra uma etapa de verificação e testagem para contestar que o modelo de fato reconheceu os melhores padrões. Aqui é preciso expor o modelo à várias possibilidades, acrescentando e tirando características, cruzando observações, para ver como ele se comporta até chegar no valor ideal para o objetivo do seu negócio.
Então, vamos imaginar que treinamos o algoritmo da corretora e que o modelo obteve um percentual de que 60% das empresas tem chance de renovar a apólice e que 40% deixará o serviço. Após testar e verificar as possibilidades provavelmente o modelo chegará em uma resposta suficiente e mais próxima para resolver o problema.
Lembrando que caso seu modelo seja consumido por um longo período ou de tempos em tempos, essa etapa precisará ser revisada e refinada constantemente para evitar viés no resultado e para aperfeiçoar e manter a inteligência viva.
7) Consuma o modelo
Após ajustar o algoritmo, você terá a implementação de Machine Learning pronta para ser aplicada e resolver seu problema. Ou seja, no exemplo da corretora teríamos uma listagem das empresas com menor probabilidade de renovar para que a organização possa priorizar e aplicar ações para tentar converter o jogo e garantir a renovação.
Essa etapa pode ser feita de duas maneiras:
- Conectando com algum dashboard para que seja tomada a ação, como é o caso do nosso exemplo que geraria um ranking das empresas que a corretora deverá priorizar;
- Ou colocá-lo em produção instalando em alguma operação da sua empresa ou em um aplicativo.
Você está pronto?
Resumidamente, este artigo percorreu um passo a passo base que qualquer projeto de Machine Learning segue para ter de fato modelos de sucesso. Mas dependendo da complexidade ou simplicidade do problema em questão, as etapas podem variar acrescentando ou retirando detalhes.
E uma última dica (essa é de ouro): O aprendizado de máquina pode ser uma tecnologia acessível para todas as empresas e não apenas as gigantes. Sua empresa também merece trabalhar de forma mais inteligente, e esse é o poder da Machine Learning. Você está pronto?
Caso precise de uma mãozinha na implementação de Machine Learning a Programmer’s possuí expertise, tecnologia, profissionais especializados e uma solução com baixo investimento, que identifica a viabilidade de um projeto em Data Science para posteriormente desenhar um roadmap completo e desenvolver modelos analíticos robustos e integrados às soluções corporativas ou a produtos digitais.
Fale com um dos nossos consultores e saiba mais da solução Programmer’s Insights.
