Stream? Data Lake? Talvez a resposta seja Arquitetura Lambda
Imagine um cenário no qual um diretor de um hospital precisa receber um alerta em poucos minutos sem notificado em real-time a quantidade de leitos em uso, ao mesmo tempo que precisa ter a possibilidade de uma análise histórica com uso de algoritmos para analisar a correlação na satisfação dos pacientes com atributo do hospital.
É em situações como esta que uma Arquitetura Lambda, poder ser uma estrutura poderosa, pois foi elaborada em meio a necessidade de processamento de grande volumes de dados, genérica, independe de soluções tecnológicas específicas para a coleta, armazenamento e processamento dos dados, que consegue atender em uma única estrutura todas as necessidades do processamento de dados – estruturados, semi-estruturados e não-estruturados – e históricos enquanto simultaneamente faz análises em real-time.
A Arquitetura Lambda apesar de genérica visa principalmente solucionar problemas do universo Big Data, para tanto, algumas propriedades são muito desejadas neste ambiente, como:
- Robustez e tolerância a falhas;
- Baixa latência para leituras e atualizações;
- Escalabilidade;
- Generalização;
- Extensibilidade;
- Consultas Ad-hoc;
- Manutenção mínima;
- Debuggability (Debugabilidade).
As três camadas
Essa estrutura é dividida em três camadas dependentes e complementares como veremos abaixo:
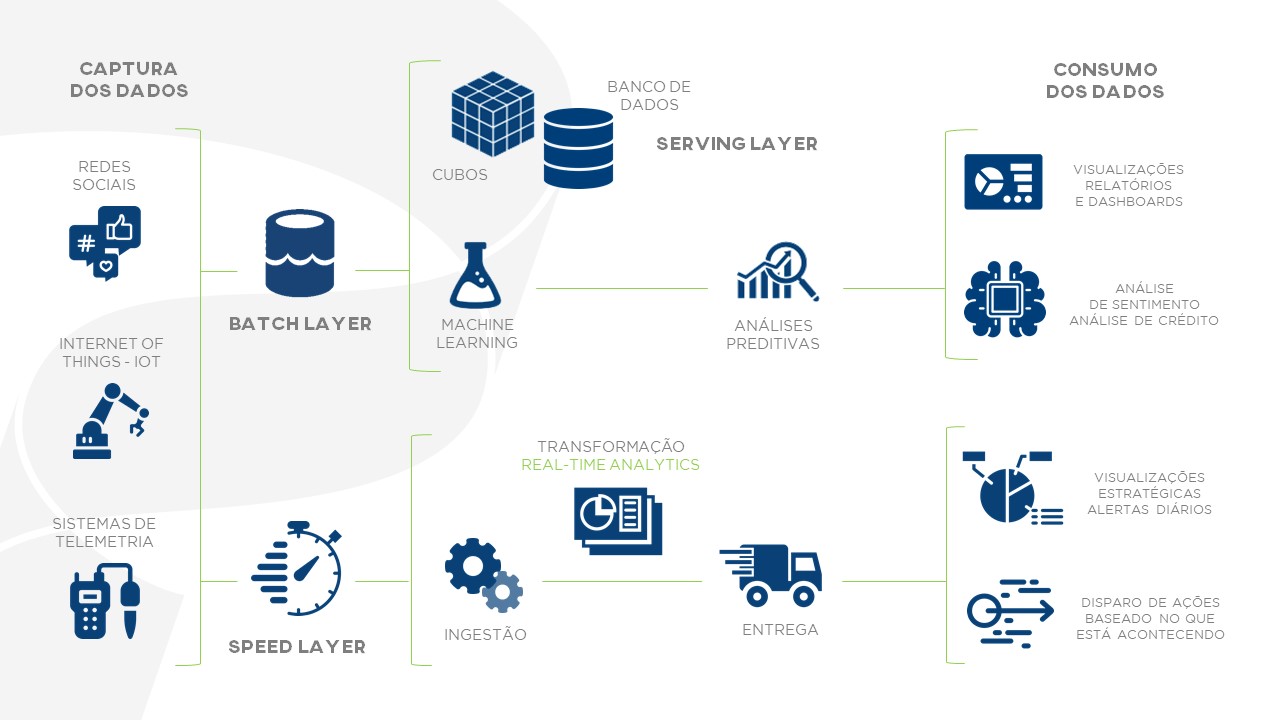
1- CAPTURA DOS DADOS: Através de diversas fontes é feita a captura dos dados (estruturados, semi-estruturados e não-estruturados) para que eles sejam enviados para as camadas de processamento Batch e Speed;
2- BATCH LAYER: Camada de alta latência que armazena todos os dados coletados em sua forma bruta para poderem ser a qualquer momento recuperados e processados para gerar insights.
É nessa camada que é possível construir um Data Lake de forma organizada;
3- SERVING LAYER: Camada responsável por consolidar os datasets dos dados processados na camada Batch Layer, fornecer aos um acesso de baixa latência e atualizações em lote (várias linhas).
É ótimo para os bancos de dados tradicionais e relacionais (que tenham as características acima), e camadas semânticas como cubos multidimensionais;
4- SPEED LAYER: Camada de baixa latência que processa os dados recentes no mesmo instante que eles chegam para que seja possível realizar análises em tempo real e assim compensar a alta latência da Batch Layer.
Caracterizada como a camada de geração de notificações em real-time, e é aqui que se encaixa a tecnologia Stream Analytics;
5- CONSUMO DE DADOS: Por últimos os dados estão prontos para serem consumidos da forma que melhor fizer sentido para seu negócio e de mais fácil entendimento possível para os tomadores de decisões.
Quando usar uma Arquitetura Lambda?
Dependendo das necessidades do negócio pode ser que as três camadas, como diz o velho ditado: “Seja muita areia para o seu caminhão”.
Mas, resumidamente uma arquitetura Lambda ajuda a endereçar valor, principalmente, para cenários que precisam ter:
- Centralização dos dados, provendo na velocidade em que o negócio precisa;
- Dados sempre com uma única verdade.
Por exemplo, uma instituição financeira, seu usuário final precisa receber um alerta de um consumo excessivo no seu cartão de crédito, como também ele precisa poder ver todo seu histórico das faturas anteriores do cartão.
Mas, independente das soluções que sua organização precise uma coisa é fato, ter uma arquitetura de dados poderosa – seja um Data Lake, Stream Analytics ou Lambda – é garantir que sua oferta está competitiva no mercado, extraindo insights de seus dados já disponíveis e tomar decisões mais confiáveis possíveis.
Quer conversar mais sobre o assunto? Fale com um dos nossos consultores (por aqui), a Programmer’s pode te ajudar tanto na consultoria para entender as particularidades do seu negócio como na implementação de serviços de Inteligência de Dados.
